How to Elevate Your GPT to the Top 1% Using This Method
Written on
Introduction to HubermanGPT
Recently, I launched my first GPT, and the feedback has been overwhelmingly positive, with over 200 interactions from users globally on X! But what sets HubermanGPT apart from the rest?
The answer lies in its utilization of Retrieval Augmented Generation (RAG) techniques. Today, we will delve into this exciting subject!
The Magic of Retrieval Augmented Generation
Retrieval Augmented Generation, or RAG, is a sophisticated approach that merges traditional language models with an external knowledge database. This allows the model to dynamically access relevant information, improving both its accuracy and depth. For HubermanGPT, RAG was a strategic decision to ensure that answers were directly aligned with insights from the Huberman Lab Podcast.
Building the Knowledge Base
While OpenAI offers a Knowledge feature for GPTs, I opted for a more tailored solution for my project.
Why forego the standard Knowledge feature? The limitations were significant: only 20 files could be uploaded, and the default retrieval accuracy left much to be desired. Thus, I decided to build my own database and RAG engine.
HubermanGPT Knowledge Base Development
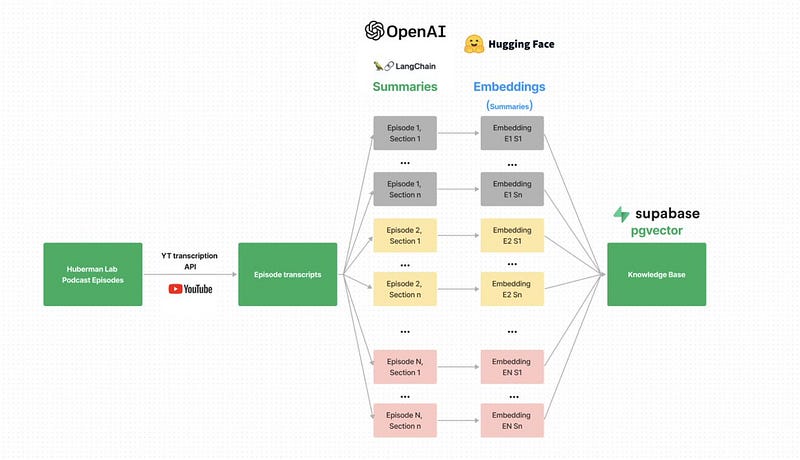
The foundation of HubermanGPT is its carefully constructed knowledge base. Here’s how it came together:
- Transcription Extraction: I began by obtaining transcripts from the Huberman Lab Podcast and breaking them down into digestible parts.
- Summarization and Embedding: Each segment was summarized using ChatGPT, followed by embedding using an open-source model from Hugging Face to ensure precise retrieval.
- Hosting and API Creation: The embeddings were stored on Supabase, and I developed a FastAPI endpoint to manage queries efficiently. This endpoint, hosted on AWS Lambda, forms the core of our retrieval mechanism.
Here’s a visual representation of the workflow:
Creating the Custom GPT
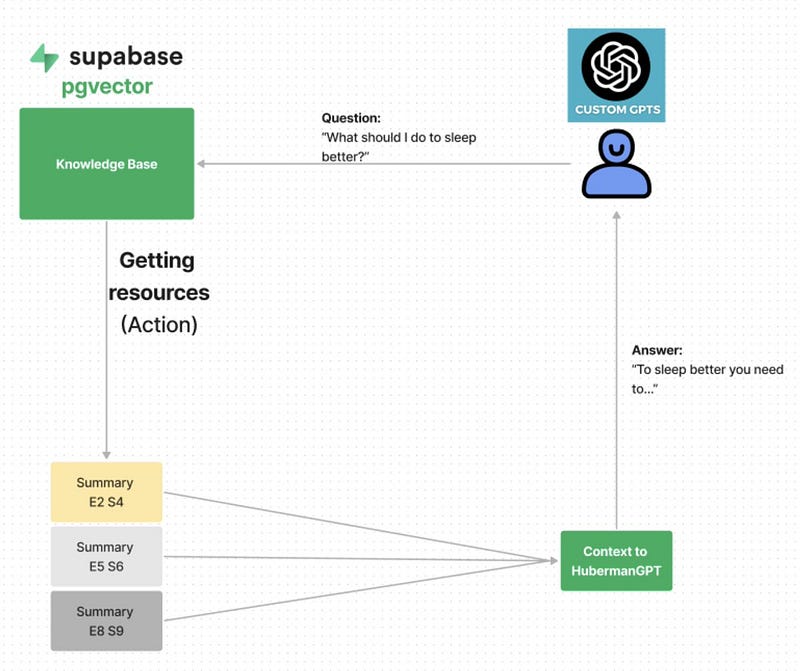
The main function of HubermanGPT is to understand health-related inquiries and fetch the most pertinent podcast segments to answer them. This involves:
- Analyzing the user’s question and seeking clarification if necessary.
- Utilizing a FastAPI endpoint to retrieve relevant summaries from podcast sections based on the query.
- Compiling these summaries into a unified response, complete with embedded links for further exploration.
The following diagram illustrates this process:
Inside the GPT, the API (AWS Lambda Function) is activated at this stage:
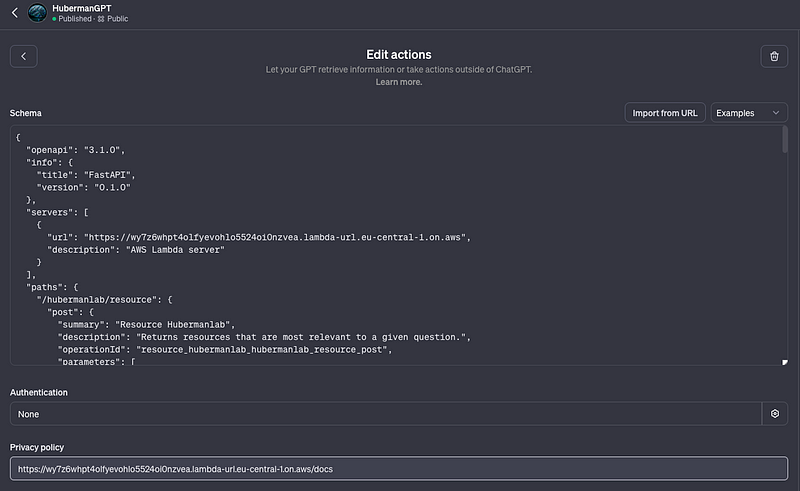
Configuring Actions for Custom GPTs
Setting up Actions in Custom GPTs is user-friendly, especially with a ready FastAPI endpoint. Simply copy and paste the OpenAPI JSON from your FastAPI documentation into the Action box within the GPT UI.

This integration facilitates seamless communication between the GPT and the external knowledge base.
Conclusion: The Future of Custom GPT Development
The strategy employed in HubermanGPT exemplifies an innovative approach to custom GPT development, showcasing the potential of combining expansive language models with a well-structured knowledge base.
If you’re interested in learning how to create your own custom GPTs, including a comprehensive guide from data gathering to API integration, feel free to reach out to me on X. I’m eager to share insights and experiences in this thrilling domain.
The first video explains how Andrew Huberman's podcast can be transformed into a GPT, offering a unique perspective on using AI for health insights.
The second video showcases the process of using GPT to emulate Andrew Huberman, providing valuable tips for aspiring AI developers.