Efficiently Flattening JSON Data in BigQuery: A Comprehensive Guide
Written on
Chapter 1: Introduction to JSON Flattening
Flattening JSON can often be a daunting task. Navigating through JSON structures to identify keys tends to be quite time-consuming. However, I have discovered a method that simplifies this process. In this guide, I will explain the concept from the ground up while keeping the information concise.
Basics of JSON Structure
JSON comprises two primary data types: Struct and Array. Flattening a struct is relatively easy, but arrays require un-nesting. In BigQuery, we can utilize the UNNEST function to flatten array data. A critical step is to identify all arrays within a JSON structure.
Under the INFORMATION_SCHEMA, there exists a system view known as COLUMN_FIELD_PATHS, which contains all keys of structs and arrays across all tables in a dataset. Below, I will outline the approach I used to leverage COLUMN_FIELD_PATHS.
Step 1: Create a Sample JSON File
Begin by taking a sample of your JSON object and saving it as a file. You can find a sample file [here](#).
Step 2: Upload JSON to BigQuery
Next, upload your file to BigQuery using the manual upload method. Ensure you select the appropriate options during the upload process.


Step 3: Access Your JSON in BigQuery
Once your JSON is uploaded, it will be available in a BigQuery table using BigQuery’s native data types (struct and array).
Step 4: Query Keys in COLUMN_FIELD_PATHS
Now you can query all your keys in COLUMN_FIELD_PATHS using the following SQL command:
SELECT *
FROM INFORMATION_SCHEMA.COLUMN_FIELD_PATHS
WHERE table_name = 'your-table-name';
Typically, we need a hierarchy of all arrays within a JSON. For this, you can use the query below:
WITH cte AS (
SELECT
table_name,
column_name,
field_path,
data_type,
CAST((LENGTH(data_type) - LENGTH(REGEXP_REPLACE(data_type, 'ARRAY<', ''))) / LENGTH('ARRAY<') AS INT64) AS level_inverse
FROM DATASET-NAME.INFORMATION_SCHEMA.COLUMN_FIELD_PATHS
WHERE table_name = 'YOUR-TABLE-NAME'
AND data_type NOT LIKE 'STRUCT%'
AND data_type LIKE 'ARRAY<%'
),
cte2 AS (
SELECT * EXCEPT(level_inverse),
DENSE_RANK() OVER (PARTITION BY table_name ORDER BY level_inverse DESC) - 1 AS levelsFROM cte
)
SELECT *
FROM cte2;
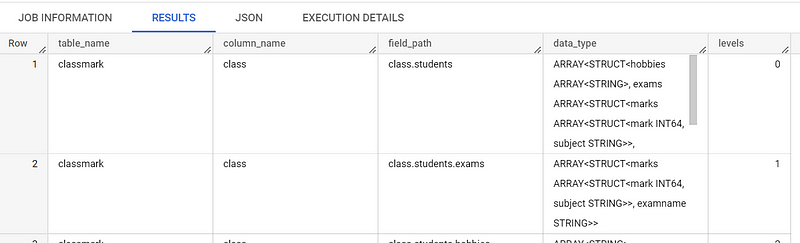
Although this method may seem straightforward, it has significantly streamlined my work process, so I wanted to share it with others.
Cheers!
#bigquery — #json — #flatten — #array — #struct — #finding_keys_of_json_in_bigquery