# Effective Strategies for Deploying ML Models without Server Dependency
Written on
Understanding the Architecture of Web Applications
When it comes to deploying your Machine Learning (ML) models, this task should be approached with caution. While there are effective tools available, such as Gradio and Streamlit, that facilitate quick sharing of your models, they may not suffice for anything beyond a simple proof of concept.
Gradio and Streamlit excel in their functionality, yet they offer limited flexibility in terms of the frontend. Consequently, your ML application may resemble numerous other prototypes available. Additionally, these platforms often struggle to handle multiple concurrent requests, potentially turning your model into a performance bottleneck that drains server resources.
In this narrative, I will explain why it’s unwise to host your model within your application server and discuss the pitfalls of this approach.
The Architecture
To begin, let's examine how a typical web application is structured. The illustration below outlines the components involved in a standard scenario where a user engages with a web application:
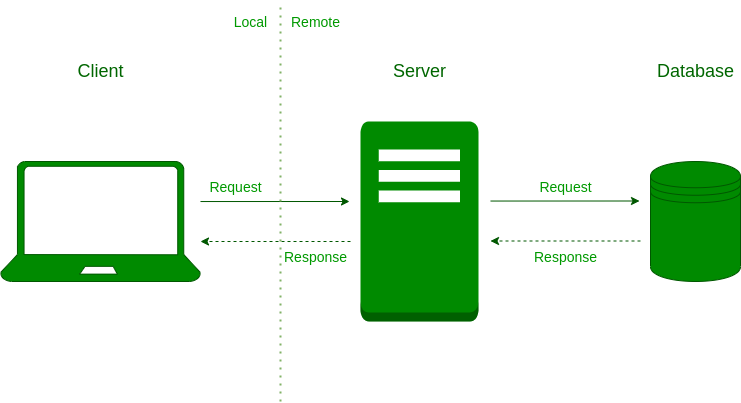
In this setup, the client represents the user, whether an individual or an application making a request. The server is where the majority of your application’s logic resides; it processes requests and returns responses. The database, on the other hand, stores the relevant application data, varying in structure but not central to our current discussion.
In this context, the client sends a request to the server over a network. The server retrieves the necessary information from the database and sends a response back to the client. This simple flow outlines a prevalent sequence of actions when a client interacts with a web application.
However, if you opt for a model-in-server architecture, the server takes on numerous responsibilities: loading your model, handling incoming request data, executing the model’s forward pass, transforming predictions, and responding to the user. This is no small feat!
The Initial Approach: Prototyping
While it may seem daunting, there is a valid reason to start with this architecture: the necessity to "fail fast" and learn quickly. During the prototyping phase of a new ML application, having certain elements in place is essential:
- A basic user interface to enhance user interaction
- A URL for easier sharing with colleagues and testers
Tools such as Streamlit and Gradio can significantly aid in this early phase. Early deployment is crucial, so leveraging their capabilities allows you to concentrate on developing your model while keeping the process straightforward.
If you're in a corporate setting, utilizing existing infrastructure also presents a compelling reason to adopt this approach. Companies often have established protocols for reliably deploying code to servers, which can simplify your workflow.
The Pitfalls of Staying with This Model
Despite the benefits, several issues arise when maintaining this architecture in production.
Firstly, if your web server is programmed in a different language (e.g., Ruby or JavaScript), integrating your model can become complicated and prone to errors.
Moreover, your production model will undergo frequent changes. Factors such as performance decay, concept drift, and the introduction of new data necessitate regular updates. In contrast, your web server code typically remains stable. Thus, adhering to the model-in-server architecture means redeploying the entire system each time an update is required—an inefficient process.
Additionally, your server may not be optimized for ML tasks. It might lack the GPU resources necessary for rapid predictions. While some may argue that GPU acceleration is unnecessary during inference, future discussions on performance optimization may reveal its importance based on specific use cases.
Lastly, the scaling of your model and web server will likely differ. If your model is complex or large, you may want to host it on GPUs and distribute the workload across multiple machines, avoiding the strain on your web server's resources.
Conclusion
In this discussion, we explored the advantages of using tools like Streamlit and Gradio for the rapid deployment of ML applications. We also examined the pros and cons of the model-in-server architecture, highlighting why it may not be ideal for production environments.
What’s the next step? In the following article, we will discuss how to decouple your model from your web server and leverage a well-established tool to serve your model in a production-ready setting.
Read the next part of this story:
Pull your ML model out of your Server: The Database Solution
When to place your model in your database, how to do it, and why.
The first video titled "How to deploy your trained machine learning model into a local web application?" offers insights into effectively deploying your ML model in a local setup.
The second video "Deploying ML Models in Production: An Overview" provides a comprehensive overview of the considerations when deploying ML models in a production environment.
About the Author
I am Dimitris Poulopoulos, a machine learning engineer at Arrikto, with experience in designing and implementing AI and software solutions for prominent clients like the European Commission, Eurostat, IMF, European Central Bank, OECD, and IKEA.
For more insights on Machine Learning, Deep Learning, Data Science, and DataOps, connect with me on Medium, LinkedIn, or @james2pl on Twitter. Please note that my views are my own and do not reflect those of my employer.