Understanding Model Fitting: Evaluating Fit to Training Data
Written on
Chapter 1: Introduction to Model Fitting
Model fitting in data science revolves around using data to forecast future events. By creating models based on current datasets, we can make predictions for comparable scenarios. This approach essentially embodies a mathematical method of learning from historical data to inform better decisions.
The accuracy of these predictions hinges on the model’s quality. A model must align well with the available dataset to produce reliable forecasts. If it fails to do so, the predictions will likely be flawed.
Section 1.1: Understanding Model Failures
Models can fail to align with an existing dataset in two primary ways:
- Underfitting: This occurs when a model lacks the complexity needed to capture the data's nuances. For example, assuming a flat tax rate in a progressive tax system would lead to significant inaccuracies in predicting tax liabilities.
- Overfitting: Conversely, an overfit model is excessively intricate, capturing noise rather than the underlying trend. While it may excel in matching the training data, it struggles to predict outcomes between data points accurately.
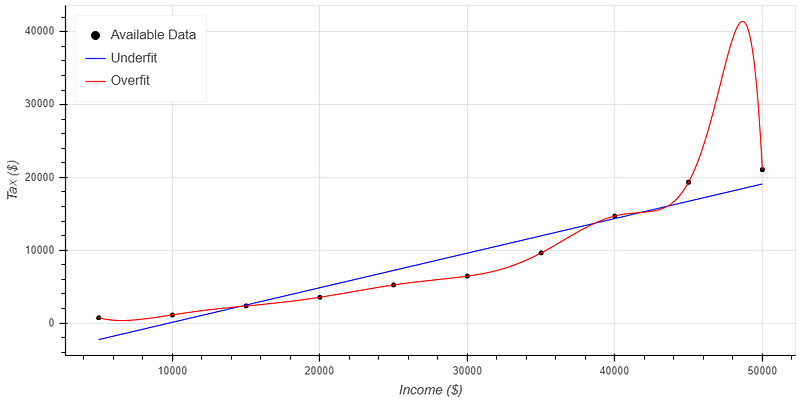
To illustrate these concepts, consider Figure 1, which depicts theoretical income tax receipts under a progressive tax system.

The graph categorizes data points into three series: the first represents actual tax receipts under a progressive system, the second illustrates an underfit model, and the third showcases an overfit model.
Section 1.1.1: Visual Analysis of Fit
Figure 1 highlights the shortcomings of both underfit and overfit models. The blue line denotes the underfit model, which fails to align closely with the data. In contrast, the red line represents the overfit model, which precisely matches the data points but introduces unrealistic trends, particularly between the $45,000 to $50,000 income range.
Section 1.2: Identifying Underfit and Overfit Models
To differentiate between underfit and overfit models, consider these key indicators:
- Underfit Models:
- Poor alignment with available data points.
- Fails to reflect the general pattern of the dataset.
- Overfit Models:
- Extremely accurate matching with available data (a potential warning sign).
- Exhibits trends in predictions that are not present in the dataset.
Chapter 2: Characteristics of a Well-Fit Model
A well-fit model strikes a balance, closely matching the available data while capturing its overall shape. Figure 2 demonstrates a suitable model through a 3rd order regression line that neither underfits nor overfits the data.
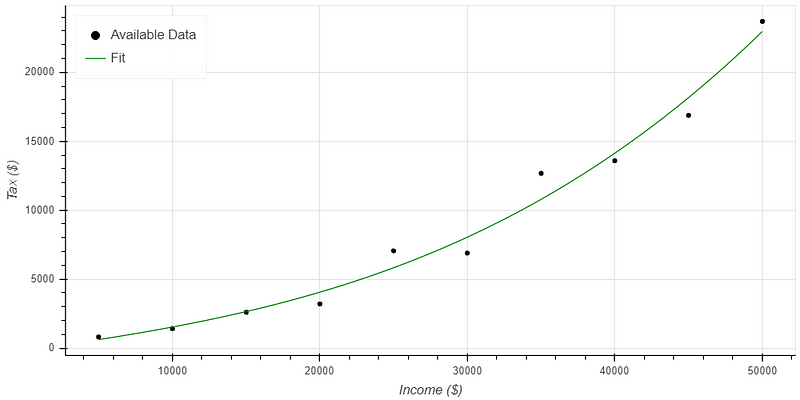
The green line in Figure 2 illustrates a model that aligns well with the available data, capturing its shape without introducing misleading trends. This model can be trusted for reasonable predictions when interpolating.
Section 2.1: Further Learning Resources
For those interested in delving deeper into model fitting, I recommend "Data Science from Scratch" by Joel Grus. Additionally, my previous Medium post offers an in-depth look at model development and validation. For a more structured learning experience, Coursera provides excellent courses on machine learning.
Wrapping It Up
In summary, effective model development and validation are crucial in data science. Models must accurately reflect the available dataset to yield reliable predictions. Common pitfalls include underfitting, where a model is too simplistic, and overfitting, where a model is overly complex. While a perfectly fitting model is rare, one that closely approximates the data and captures its shape will provide trustworthy predictions.
Learn how to prime scale models effectively before painting in this instructional video.
Discover the benefits of using spray cans for priming model kits in this informative video.